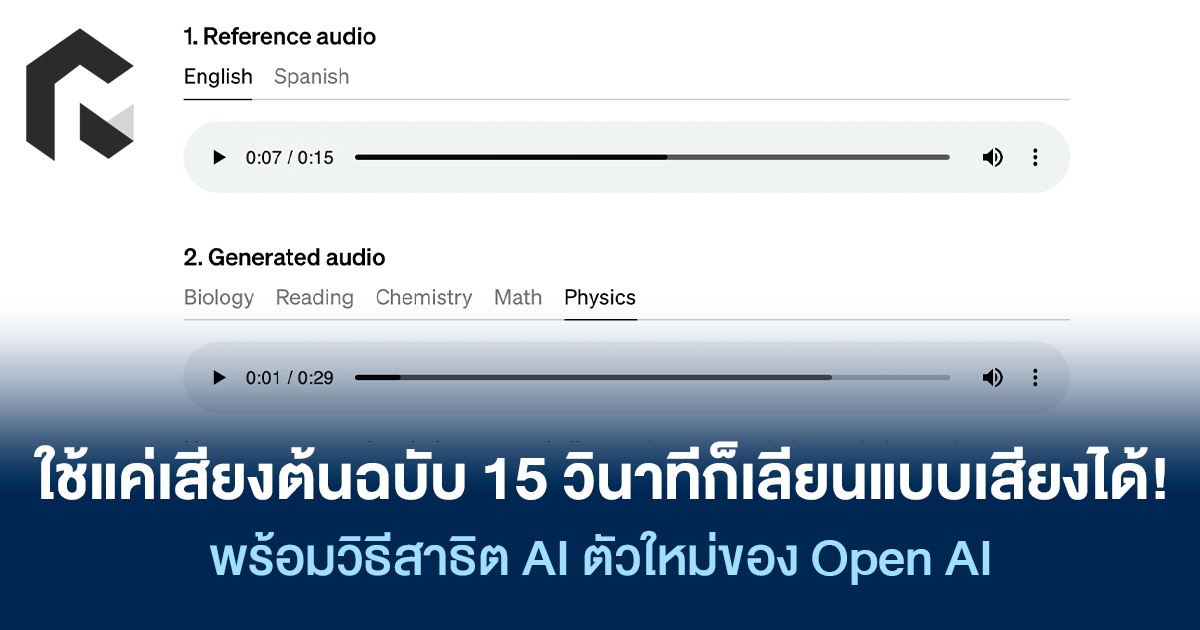
ทุกวันนี้ความสามารถของ AI เริ่มนำมาเป็นตัวช่วยในการทำงานให้เร็วขึ้นได้ ตั้งแต่การเจนภาพ หรือวิดีโอด้วยการป้อนพรอมพ์ ตอนนี้ Open AI ก็ได้สาธิต “Voice Engine” โดยการป้อนอินพุตด้วยเสียงต้นฉบับเพียง 15 วินาที ก็สามารถเลียนแบบมู้ดโทนการพูด และแสดงออกทางอารมณ์เหมือนต้นฉบับได้!
ซึ่ง Voice Engine ยังเป็นเพียงแค่การสาธิตวิธีการทำงานด้วยโมเดล AI ใหม่อยู่ เพราะ Open AI ตั้งใจนำโมเดลนี้ไปใช้กับการตอบคำถามของผู้ใช้ด้วยเสียงบน ChatGPT และมองประโยชน์ในการต่ยอดการใช้งานไปถึงเสียงที่ใช้บรรยายทับคอนเทนต์ การแปลภาษาท้องถิ่น หรือทางการแพทย์เพื่อช่วยเหลือผู้ป่วยด้วย
โดยสิ่งที่ OpenAI สาธิตคือการใส่ Reference audio เวลา 15 วินาทีที่มีทั้งภาษาอังกฤษ และภาษาสเปน เทียบกับ Generated audio ที่สามารถนำน้ำเสียง ลักษณะการพูด เว้นวรรคที่คัดลอกมาจากต้นฉบับนำมาพูดเรื่องอื่น ๆ ได้ เช่น Biology, Reading, Chemistry, Math เป็นต้น
แต่อย่างไรก็ตามถึงจะมีโมเดล Voidce Engine ที่สามารถใช้ประโยชน์ในการแปลทับคอนเทนต์ได้หลากหลายภาษามากขึ้น แต่เรื่องของ Privacy ในการนำเสียงไปใช้ก็มีความเสี่ยง โดยเฉพาะในยุคที่ยังไม่มีกฎหมายเกี่ยวกับการใช้ AI ที่เข้มงวดมากพอ
และการที่พัฒนาโมเดล AI ให้สามารถสร้างคำพูด หรือประโยคจากเสียงจริง ๆ ของผู้คนได้แนบเนียนก็ยากต่อการแยกแยะ และง่ายต่อการนำไปแอบอ้างในการเป็นบุคคลนั้นเพื่อประโยชน์ส่วนตัวได้ ฉะนั้นโมเดลนี้จึงยังไม่ถูกนำมาใช้งานได้กับคนทั่วไปจนกว่าจะถึงเวลาที่เหมาะสม หรือมีมาตรการในการรองรับความเสี่ยงมากพอ
รวมถึงต้องมีการให้ความรู้ ความเข้าใจกับทุกคนด้วยว่าความสามารถ และข้อจำกัดของเทคโนโลยี AI ก็มีสิทธิ์นำไปใช้เพื่อฉ้อโกง และล่อลวงได้ แต่ท้ายที่สุดแล้วก็หวังว่าการนำเสียงสังเคราะห์มาปรับใช้งานในชีวิตจริง จะมีการกำหนดนโยบายการใช้ที่ชัดเจนทั้งกับผู้ที่เป็นนักวิจัย นักพัฒนา และนักสร้างสรรค์ต่อไปด้วย
ที่มา: https://openai.com/blog/navigating-the-challenges-and-opportunities-of-synthetic-voices





